








解密DeepSeek-V3推理網絡:MoE架構如何重構低時延、高吞吐需求?
DeepSeek-V3發布推動分布式推理網絡架構升級,MoE模型引入大規模專家并行通信,推理流量特征顯著變化,Decode階段對網絡時度敏感。網絡需保障低時延與高吞吐,通過端網協同負載均衡與擁塞控制技術優化性能。高效運維實現故障快速定位與業務高可用,單軌雙平面與Shuffle多平面組網方案在低成本下滿足高性能推理需求,為大規模MoE模型部署提供核心網絡支撐。






一、推理場景和MoE模型引入網絡新訴求
2025年初,DeepSeek-V3發布,迅速引發國內外的廣泛關注和部署熱潮。作為核心基礎設施之一,分布式推理網面臨全新的需求。整體來看,推理與訓練的流量差異、MoE模型架構的引入以及DeepSeek開源技術方案等多重因素,影響了網絡建設的方向和要求。
傳統稠密模型的訓練與推理流量中,95%以上為Tensor Parallel(TP)通信,主要在機內高帶寬域通過all-reduce完成,機外低帶寬域僅在同號卡間執行低流量的數據并行(DP)和流水線并行(PP)通信。而DeepSeek采用的MoE(Mixture of Experts)模型架構顯著改變了流量特征。訓練和推理階段均不采用TP通信,取而代之的是大規模專家并行(EP)通信,訓練階段EP流量占比超過95%,推理階段則達到100%。EP通信跨越多個高低帶寬域,且采用all-to-all通信模式,通信結構復雜且流量巨大,對網絡性能提出了更高、更差異化的要求。
DeepSeek模型參數規模達到6710億,在推理部署中引入了PD分離和大規模EP并行,推動滿血版高性能推理走向分布式。相比傳統單機推理,分布式推理帶來了顯著差異,使得推理流量模式與分布式訓練更為接近,但兩者在流量特征上依然存在明顯區別。
通信流量可由以下公式估算:(minibatch大小 × 上下文長度 × 隱藏層維度)× 節點數 × (dispatch_alltoall通信次數 × FP8字節數 + combine_alltoall通信次數 × BF16字節數)× GPU負責的層數。下表統計主要EP流量作為參考。
| 總通信量 | 單次通信量 | |
| 訓練 | 315GB |
dispatch:112MB combine:224MB |
| 推理Prefill | 57.09GB |
dispatch:168MB combine:336MB |
| 推理Decode | 1218MB |
dispatch:3.5MB combine:7MB |
訓練場景流量模式固定且明確,單次迭代總流量高達315GB,單次EP通信流量約112MB。
推理場景流量受用戶輸入影響,波動較大。Prefill階段以4K上下文、batch size為4計算流量大小,單次迭代總流量約57.09GB,單次通信流量與訓練相近;Decode階段以128并發計算,單次迭代流量顯著降低至約1.2GB,單次通信流量僅為幾MB,Prefill與Decode階段流量差異明顯。
基于以上全新且復雜的網絡需求,深入識別和分析DeepSeek推理網絡的關鍵技術,是保障推理高性能、低成本與高可靠性的關鍵。下文我們將從低網絡時延、高效網絡運維和低成本組網角度,展開介紹DeepSeek推理網絡關鍵技術。
二、低時延網絡助力推理高吞吐
根據上述流量分析,Decode階段的單次通信流量僅為3.5MB/7MB。結合DeepSeek官方開源通信庫DeepEP的性能,當前場景下Decode階段的dispatch通信時長在100us內,combine通信時長在200us內。Decode階段的SLO通常要求低于50ms,但EP通信次數高達116次,每次通信都會導致時延疊加,因此對網絡時延提出了很高的要求。綜上,在Decode階段,很少的單次通信流量、很短的通信時長、很高的SLO要求都對網絡提出了較低的時延需求。
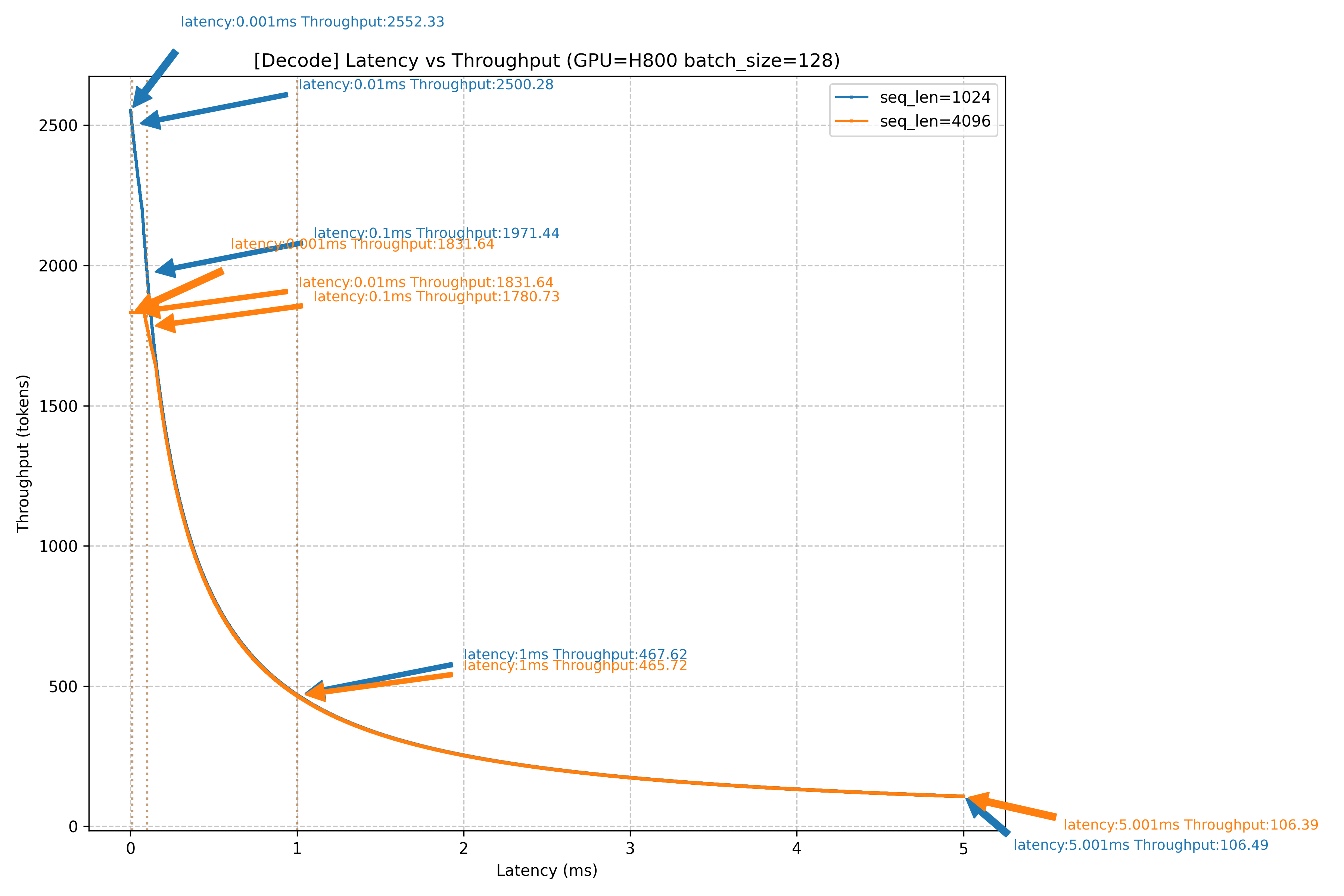
H800網絡時延對Decode吞吐的影響
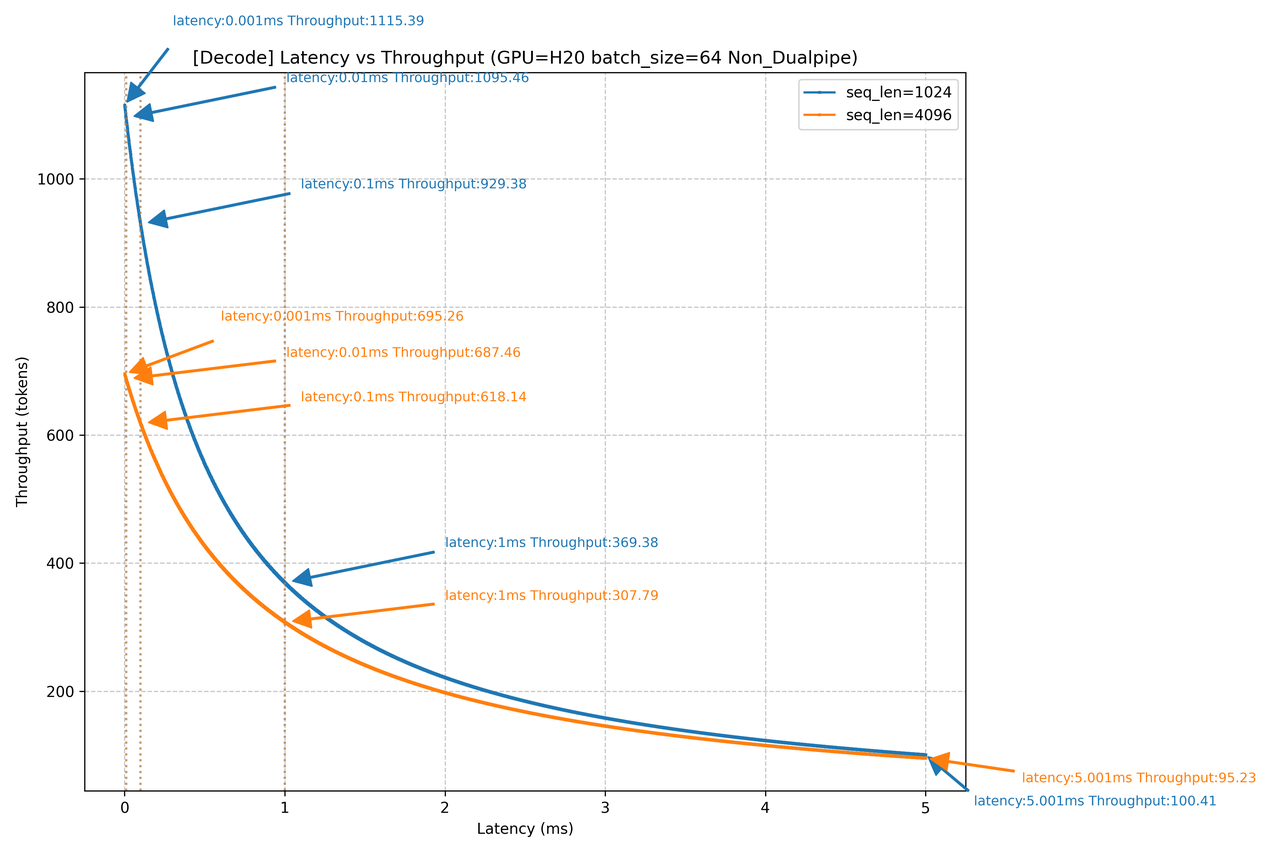
H20網絡時延對Decode吞吐的影響
上圖是對4K/1K上下文,1K輸出的Decode場景,在H800/H20設備下,以128 batch作為場景,進行的網絡時延對Decode吞吐影響仿真。如圖所示,當網絡側產生1ms的時延增加時,無論是H800還是H20,在不同的上下文場景下,吞吐都會產生巨大影響,吞吐下降幅度高達80%左右,幾乎已經直接導致當前Decode節點不可用。當網絡上產生100us的時延時,4K上下文場景下,吞吐下降可能達到20%+。由此可見,Decode節點對網絡時延的敏感度很高。在DeepSeek大規模EP并行all-to-all通信模式下,網絡時延的主要影響因素是負載均衡和擁塞控制:
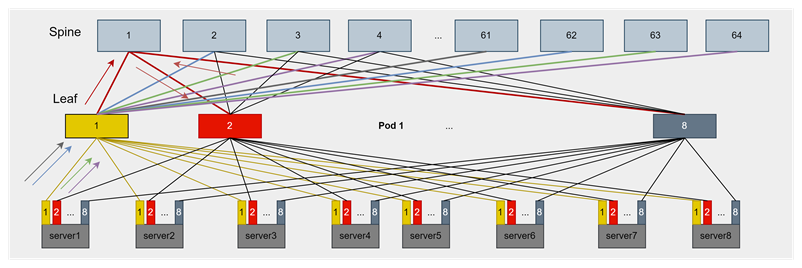
如上圖所示,在大規模EP的DeepSeek推理場景,EP域的通信可能橫跨多個Leaf,流量走向Spine,容易產生典型的ECMP哈希不均問題,導致較高動態時延。且DeepSeek的MoE模型推理易產生實例間負載不一致和實例內專家負載不一致問題,在網絡上表現為流量中大小流混合。該現象更容易加劇ECMP不均導致的動態時延問題,不佳的負載均衡策略,在網絡上容易引入100us+甚至更高的動態時延。如上文分析,這樣的動態時延水平對吞吐的影響可能達到20%+。在DeepSeek官方場景中,采用IB交換機和CX網卡的Adaptive Routing(AR)技術,有效緩解了ECMP負載不均問題。在RoCE環境下,端網協同的負載均衡方案在如此苛刻的低時延要求下,是至關重要的。
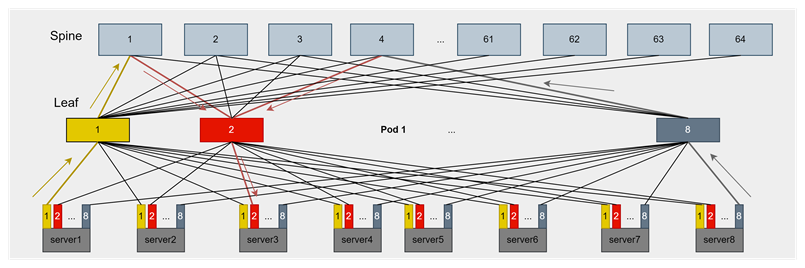
此外,MoE模型的大規模專家并行通信本質上是一種all-to-all模式,網絡中天然存在incast流量。合理的擁塞控制策略能夠避免因流量降速或PFC(Priority Flow Control)觸發而帶來的高動態時延,保障網絡時延的穩定性和推理性能。
三、高效端網運維保障高可用推理業務
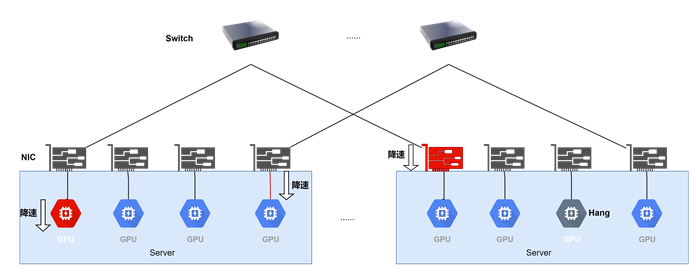
慢故障、hang異常
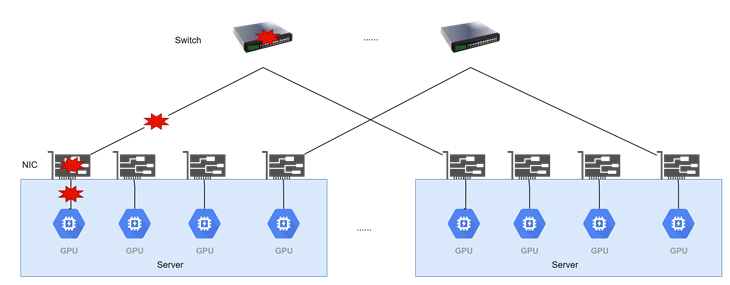
鏈路故障
隨著DeepSeek推理引入大規模專家并行(EP),分布式推理集群面臨與訓練集群類似的故障挑戰。根據Meta公開的研究數據,以1024卡集群為例,平均每7.9小時會發生一次故障。結合故障對推理的影響,可將故障類型歸納為三類:
慢節點異常:故障發生后推理任務不中斷,但部分節點或階段性能下降,導致整體推理被拖慢,表現為慢節點效應。
Hang異常:故障導致推理長時間卡頓于某一階段,任務無法繼續推進,但整體推理仍未中斷。
鏈路故障:鏈路中斷直接導致整個推理實例退出。
在慢節點異常和短時間Hang異常場景下,雖然推理任務仍在運行,但推理性能顯著受損,TTFT(Time To First Token)和TPOT(Time Per Output Token)指標明顯惡化,吞吐量可能下降50%以上。因此,針對慢故障和Hang異常的實時監控、快速定位與排查,對于保障推理性能具有重要價值。
而在長時間Hang異常或鏈路故障導致推理實例直接退出的情況下,業務影響更為嚴重。對于大規模實例部署環境,可通過請求快速切換至其他健康實例,雖可能犧牲部分用戶體驗,但能保障業務連續性。相較之下,少量實例部署(如單個Decode實例)發生故障時,往往直接導致業務中斷,嚴重影響穩定性和用戶體驗。因此小規模場景下,故障的定位、逃生和規避,是保障業務可用性的關鍵手段。
四、高性價比推理組網壓榨百萬token成本
1.雙口網卡雙平面組網:
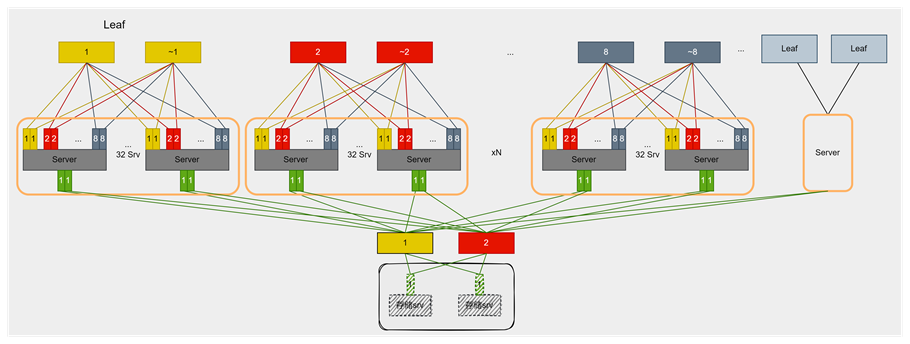
單軌雙平面組網
基于上述對網絡低時延和高可靠性的需求,采用如圖所示的單軌雙平面組網方案,能夠最大程度保障性能與可靠性。相比傳統CLOS架構,該方案在性價比方面更具優勢。具體特點如下:
優勢:
網絡結構簡潔:流量集中于Leaf交換機,降低跨交換機通信復雜度,顯著減少時延。
成本效益高:支持銅纜互聯,減少交換機數量,整體網絡投入更低。
時延低:數據面鏈路最長僅為2跳,最大跳數為1跳,確保低時延傳輸。
流控需求低:無負載均衡問題,流量走單一路徑,簡化流控設計。
易于擴展:新增節點無需增加二層網絡,支持集群橫向擴展。
Bond適配性強:采用bond雙平面組網提升網絡可靠性,且由于無二層組網,bond方案不會帶來額外交換機成本。
劣勢:
靈活性受限:Prefill或Decode實例不可跨Leaf部署,單實例最大規模受限于256卡。
兼容性不足:組網針對推理流量特性優化,難以兼容訓練與推理一體化場景。
KV Cache傳輸依賴存儲網:在采用PD分離部署時,如果存在跨Leaf的PD實例,則必須配備存儲網絡以支持KV Cache傳輸。
2.Shuffle多平面組網:
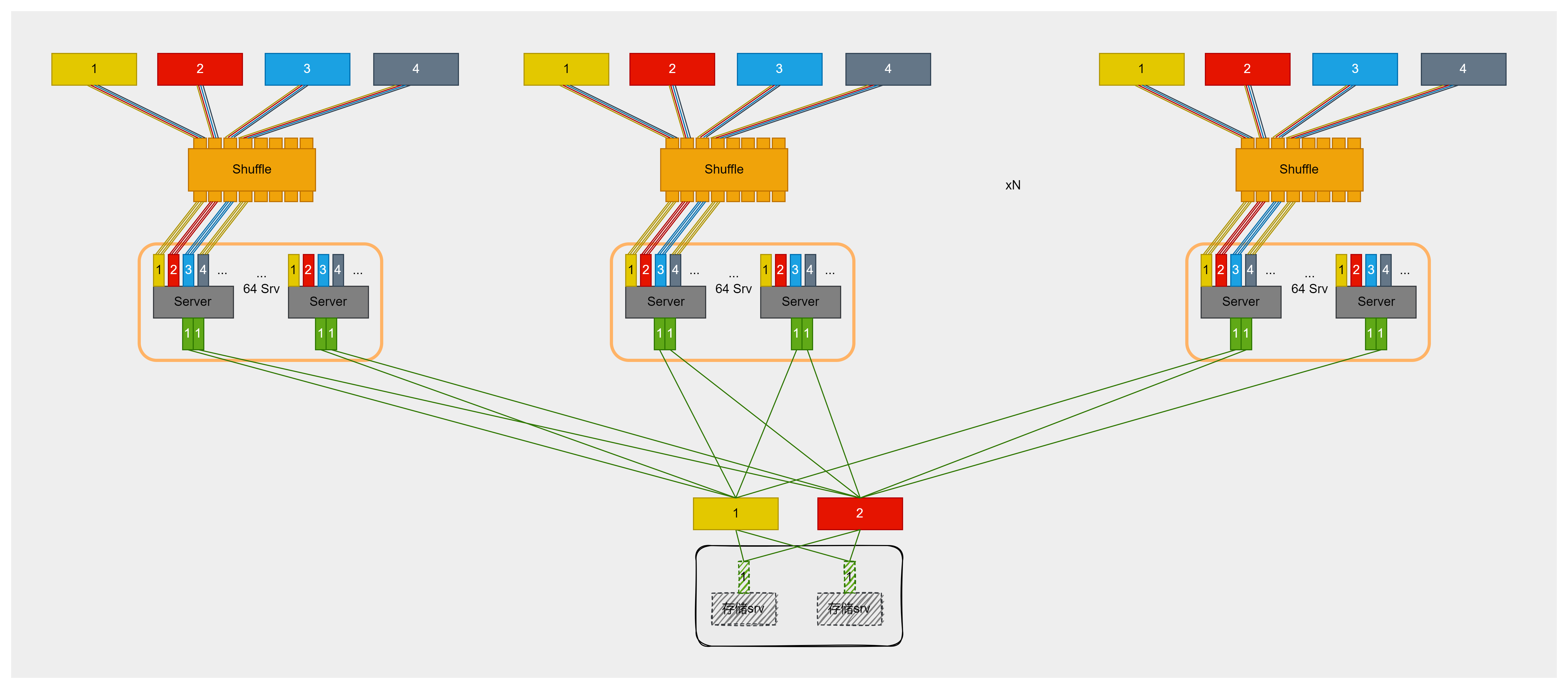
基于雙網口網卡的雙平面組網方案,單Pod最大規模受限于256卡,導致靈活性不足。為突破這一瓶頸,在Server與交換機之間引入Shuffle(光交叉盒),實現物理層面的分光。依托400Gbps網卡和TH5芯片交換機,組網方案升級為四平面,單Pod最大規模擴展至512卡,滿足絕大多數推理部署需求。此方案支持更大規模的EP并行和PD實例數量增加,且PD實例無需跨Pod調度,大幅提升Pod內組網靈活性,顯著降低對KV Cache存儲網絡的依賴。
未來,隨著800Gbps網卡和TH6芯片交換機的應用,Shuffle多軌方案可拓展至8軌。在保證單GPU享有800Gbps帶寬的前提下,單Pod最大規模可擴展至1024卡,滿足超大規模推理服務需求。該方案在無二層組網架構下,依然提供很高的PD分離部署靈活性,PD實例無需跨Pod調度,也無需KV Cache傳輸專用網絡,實現了卓越的性價比與性能。
總結
DeepSeek MoE模型的分布式推理部署帶來了推理網絡架構和性能保障的全新挑戰。推理階段的通信模式和流量特征與傳統訓練存在顯著差異,尤其是Decode階段對網絡時延敏感,要求網絡具備低時延和高吞吐能力。端網協同的負載均衡算法和擁塞控制技術是保障網絡性能的關鍵。與此同時,推理業務高可用性要求完善的故障監控、快速定位和故障逃生策略。針對這些需求,設計簡潔高效且具備高可靠性的單軌雙平面組網方案,能夠在保證性能的同時降低成本。未來,隨著DeepSeek及類似大規模MoE模型的廣泛部署,推理網絡的優化和創新將成為核心競爭力。
相關標簽:


點贊


更多技術博文
-

 高密場景無線網絡新解法:銳捷Wi-Fi 7 AP 與 龍伯透鏡天線正式成團
高密場景無線網絡新解法:銳捷Wi-Fi 7 AP 與 龍伯透鏡天線正式成團銳捷網絡在中國國際大學生創新大賽(2025)總決賽推出旗艦Wi-Fi 7無線AP RG-AP9520-RDX及龍伯透鏡天線組合,針對高密場景實現零卡頓、低時延和高并發網絡體驗。該方案通過多檔賦形天線和智能無線技術,有效解決干擾與覆蓋問題,適用于場館、辦公等高密度環境,提供穩定可靠的無線網絡解決方案。
-
#無線網
-
#Wi-Fi 7
-
#無線
-
#放裝式AP
-
-
 打造“一云多用”的算力服務平臺:銳捷高職教一朵云2.0解決方案發布
打造“一云多用”的算力服務平臺:銳捷高職教一朵云2.0解決方案發布銳捷高職教一朵云2.0解決方案幫助學校構建統一云桌面算力平臺,支持教學、實訓、科研和AI等全場景應用,實現一云多用。通過資源池化和智能調度,提升資源利用效率,降低運維成本,覆蓋公共機房、專業實訓、教師辦公及AI教學等多場景需求,助力教育信息化從分散走向融合,推動規模化與個性化培養結合。
-
#云桌面
-
#高職教
-
-
 醫院無線升級必看:“全院零漫游”六大謎題全解析
醫院無線升級必看:“全院零漫游”六大謎題全解析銳捷網絡的全院零漫游方案是新一代醫療無線解決方案,專為智慧醫院設計,通過零漫游主機和天線入室技術實現全院覆蓋和移動零漫游體驗。方案支持業務擴展全適配,優化運維管理,確保內外網物理隔離安全,并便捷部署物聯網應用,幫助醫院提升網絡性能,支持舊設備利舊升級,降低成本。
-
#醫療
-
#醫院網絡
-
#無線
-
-
 精準出擊!銳捷極簡以太彩光網絡4.0再添新翼,“超融合”方案創新而來
精準出擊!銳捷極簡以太彩光網絡4.0再添新翼,“超融合”方案創新而來銳捷網絡發布極簡以太彩光4.0超融合方案,專為宿舍等高密接入場景設計。該方案采用統一以太網二層架構,弱電間無源部署,支持單核心接入超萬間房間。創新推出有線無線一體化Wi-Fi 7面板型光無線接入點,實現靈活部署與統一運維,同時支持超聚合與超融合模式靈活適配,為高校及行業園區提供極簡智能的全光網絡解決方案。
-
#交換機
-
#全光網
-
















